ここでは自分の勉強の復習もかねて、何回かにわたって、Pythonの使い方をまとめていきます(全部で何回分になるかは不明)。紹介するPythonは、Python3(2ではない)。また、OSは、macです。また、jupyter notebookを使っていきます。
Contents
文字列を表示する
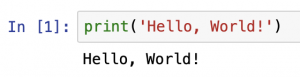
以前、「Hello, World!」を出力する際に、既に行いましたが、print()関数を使うと、文字列の出力ができます。ここで大事なことは、出力される文字列は、「'」または「"」で文字列の前と後を囲む必要があるということです。
文字列と文字列をつなげる
別々の文字列をつなげるには、「+」 を使えば、文字列をつなぐことができます。以下の例では、a, b というそれぞれの変数に対して、定義された文字列を「+」を使ってcという新しい文字列を定義しています。

なお、print()関数の中で、「,」で2つの文字列を並べることでも、文字列をつなげて出力することも可能です。

「.」の後に、joinをつけるメソッドの一種の方法使って、文字をつなげることも可能です。(ここでは、「配列」が出てきますが、配列についてはまた別の機会に詳しくやりたいと思います。)

.join()メソッドの使い方は、「x」をつなぎの文字列「y」,「z」を、それぞれ繋ぎたい文字列とすると、
x.join([y,z])
とすると、「y」と「z」を「x」でつなぐように実行され、「yxz」を返します。(上の例では、xにあたる部分に、何の文字もないことを示す「''」が指定されています。)
文字列を分割する
文字列の分割にも、「メソッド」と使います。ここでは、「.」の後に、splitをつけることで、分割するメソッドが使えます。

「Hello, World!」という文字列に対し、半角スペースを指定することで、その前後で2つに分割されていることがわかります。
半角スペース以外にも、別の文字列を指定すると、その前後で分割されます。
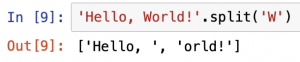
上の例では、splitに「W」が指定されているため、Wの前後の2つの文字列に分けられました。
それでは、1つの文字列の中に複数同じ文字がある場合、その文字を指定するとどうなるかやってみましょう。

4つの文字列に分割されました。少し複雑なので、どのように分割されたのか考えてみましょう。
一番初めの「l」に対して、その前後の文字列である、「'He'」と「 'lo, World!'」に分けられます。分割された後ろの方には、まだ「l」が含まれているため、さらに分割が進みます。
'lo, World' の一番先頭の文字「l」に対して、その前後で文字列が分割されようとしますが、「l」が一番先頭なので、前には何もありません。そこで、分割後、何の文字列もないことを示す 「''」と「'o, World!'」に分割されます。
'o, World!'には、最後の「l」が含まれているので、その前後の「'o, Wor'」と「'd!'」に分けられます。
そして結果として、「'He'」「''」「'o, Wor'」「'd!'」 の4つに分けられたのだとわかります。
文字列を置き換える
文字列の中に含まれる特定の文字を、別のもじに置き換える(置換)ことができます。置換にも、「メソッド」があり、「.」の後に、replaceをつけることで、置換するメソッドが使えます。ある特定の「文字列」に対し、「置き換えられる文字列」、と「置き換える文字列」を指定しますが、その方法は以下の通りです。
'文字列'.replace(置き換えられる文字列、置き換える文字列)
また、「'Hello, World!」を使ってやってみましょう。
置き換えられる文字列を、「'W'」、置き換える文字列「'Y'」とすると次のようになります。

「'Hello, Yorld!'」と、うまく置換されていることがわかります。
それでは、1つの文字列に、同じ文字列が複数ある場合についても確認しておきましょう。
置き換えられる文字列を、「'l'」、置き換える文字列「'k'」とすると次のようになります。

3つあった「l」がすべて、「k」に置換されていることがわかります。
文字列に含まれるアルファベットの大文字・小文字を変換する
アルファベットの小文字を大文字に変換する場合は、メソッド 「.upper()」、大文字を小文字にする場合は、メソッド「'lower()」を使います。

特定の文字列が何番目にあるかを探す
文字列の中の特定の文字列の場所が、何番目にあるかを探す「.find()」というメソッドがあります。
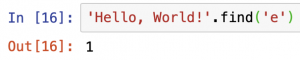
上の例では、「'Hello, World!'」という文字列の中に、文字列「'e'」が初めから数えて何番目にあるかを返しています。ここで、pythonにおいて大変重要なのは、一番最初は、「1」ではなく、「0」になります。以下に「'Hello, World!'」のそれぞれの文字が、何番目にあるかを示す表です。一番最後の文字列は、12番目ですが、pythonでは、-1番目ということもできます。
| 0番目 | 1 番目 | 2番目 | 3番目 | 4番目 | 5番目 | 6番目 | 7番目 | 8番目 | 9番目 | 10番目 | 11番目 | 12番目 |
| H | e | l | l | o | , | W | o | r | l | d | ! | |
| -13番目 | -12番目 | -11番目 | -10番目 | -9番目 | -8番目 | -7番目 | -6番目 | -5番目 | -4番目 | -3番目 | -2番目 | -1番目 |
ただ、注意したいのは、findメソッドでは、マイナス側の位置は返しません。「-1」を返すことがありますが、それは、探したい文字がないことを意味します。
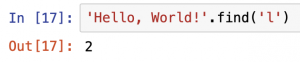 では、次に、「'Hello, World!'」という文字列の中の、文字列「'l'」についてfindメソッドをかけるとどうなるでしょう。
では、次に、「'Hello, World!'」という文字列の中の、文字列「'l'」についてfindメソッドをかけるとどうなるでしょう。
結果は、0番目から数えて一番初めに出てくる、「l」の位置である「2」番目を返していますが、残りの3番目、10番目の「l」については、飛ばされています。
また、find()メソッドには、どの範囲から探すかを指定することができます。
'Hello, World!'.find('l', 0, 2)
と指定すると、0番目〜2番目の範囲に、「l」がどこにあるかを探すことができます。ここで注意が必要なのは、範囲は「0番目以上、2番目未満」を指定しているということです。
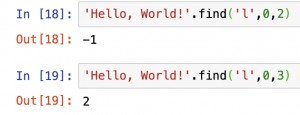
上の例の1つ目の結果は、「0番目以上、2番目未満」を指定している場合、つまり、「0番目以上、1番目以下」の範囲は、「'He'」なので'「l」は含まれないため、「-1」が返されています。
2つ目の結果は、「0番目以上、3番目未満」を指定している場合、つまり、「0番目以上、2番目以下」の範囲は、「'Hel'」なので'「l」が含まており、「2」が返されています。
この手法を使って、「l」が2つ以上含まれないように、範囲を指定すれば、3つある「l」がどこにあるかを調べることができます。

上の例では、「0番目以上、3番目未満」「3番目以上、10番目未満」「10番目以上、12番目未満」と「l」が重ならないように範囲を指定した結果、「2番目」「3番目」「10番目」と3つの「l」の位置を確認できています。ただ、これは、初めから「l」がどの位置にあるかわかっていないと、きれいに範囲を指定することはできません。
以下の例では、「'Hello, World'」の文字列が、明らかになっていない場合に、「l」がどこにあるかを調べるには、どうしたら良いかの1例を示したものになります。

まだ紹介していない、「if文」や「for文」、「.append()」のメソッド、range()や、len()の関数などを使っていますが、一応何をやっているのかを説明します。
まず、「place_of_l」という名前の空の配列「[ ]」を用意します。
次に、for文ですが、「i」を「in range(len('Hello, World')」の範囲で繰り返し実行します。len()は、文字列の長さを示します。range()は、範囲を示します。

つまり、i は、0から11の数字を繰り返します。(0番目以上12番目未満を範囲とするため、12は含みません。)
for 文の中で、まず「'Hello, World!'」のうち「i番目以上、i+1番目未満」の範囲の文字列に「l」が何番目にあるかを返す、「check_place」を定義します。次に、if文で、check_placeが、正の値をとるとき、冒頭に定義された配列「place_of_l」に「.append()メソッド」を使って、「l」の位置を示す数字をくっつけていきます。結果として、「'Hello, World!'」の中のすべての「l」の場所を示す数字が格納された配列「place_of_l」が作成されました。
特定の文字列が何個あるかを示す
文字列の中の特定の文字列が、何個あるかを返す「.count()」というメソッドがあります。
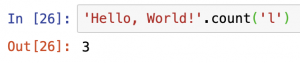
上の例では、「'Hello, World!'」の中に、「l」が3個あることを示す、「3」を返しています。
特定の位置の文字列を確認する
文字列に対して、例えば、「1番目の文字が何か」を示すこともできます。その場合、文字列の末尾に「[1]」をつけます。
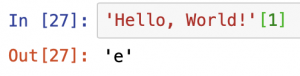
再度、「'Hello, World!'」のそれぞれの文字の位置について、確認します。
| 0番目 | 1 番目 | 2番目 | 3番目 | 4番目 | 5番目 | 6番目 | 7番目 | 8番目 | 9番目 | 10番目 | 11番目 | 12番目 |
| H | e | l | l | o | , | W | o | r | l | d | ! | |
| -13番目 | -12番目 | -11番目 | -10番目 | -9番目 | -8番目 | -7番目 | -6番目 | -5番目 | -4番目 | -3番目 | -2番目 | -1番目 |
文字列'e'は、1番目ですが、-12番目でもあります。したがって、-12を指定すると、次のように「e」が返されます。

さらに、「1番目以上4番目未満の文字が何か」を示すこともできます。。その場合、文字列の末尾に「[1:4]」をつけます。
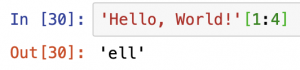
1番目、2番目、3番目の文字列「'ell'」が返されました。「'ell'」は、-12番目、-11番目、-10番目の文字でもあるので、以下のように指定しても同じ結果が得られます。

文字列を使った応用:メソッドの組み合わせ
ここで紹介したメソッドは、組み合わせて使うことも可能です。

上の例では、「.replace()」、「.upper()」、「.split()」の3つのメソッドが組み合わされています。また、メソッドを組み合わせる場合、左から順に実行されていきます。それがわかっていれば、順に追っていけば何が行われたのかがよくわかります。
最初は、「'Hello, World!'」に対して、「.replace('l','k')」のメソッドが実行されて、「'Hekko, Workd!」となり、次に、「.upper()」メソッドが実行されて、「'HEKKO, WORKD!」となりました。最後は、「.split(' ')」メソッドが実行されて、半角スペースの前後で文字列が分割されて、「'HEKKO,'」と「'WORKD!」に分けられたのだとわかります。
おわりに
今回は、文字列に対して、様々なメソッドを実行することで、「組み合わせ」「分割」「置換」「大文字・小文字の変換」を始め様々なことが行えることがわかりました。また、それらのメソッドを一度に組み合わせることも可能であることを確認しました。
↓Python試しに勉強してみてはいかがでしょうか?5回分無料のようです↓

↓プログラミング未経験者が転職まで考えるなら↓

。紹介するPythonは、Python3(2ではない)。また、OSは、macです){kind=link}